

Merhabalar, ASCII Nedir? ASCII Tablosu Nedir? gibi sorulara detaylıca cevap vereceğiz. ASCII’nin ortaya çıkma sebebinden, tarihinden ve bugününe kadar geçirdiği değişimlerin hepsini içeren bilgilendirici ve uzun bir yazı olacak.
ASCII Nedir? Tüm Detaylarıyla ASCII
Karakter kodlama (Character Encoding), her yazılımcı için çok önem taşıyan ve bilinmesi gereken bir konudur. Yazılım dillerinin bir çoğunda encode() metotları yer almaktadır. Dosya okuma işlemlerinde Encoding parametreleri yer almaktadır. Ne zaman metinler ile ilgili işlemler yapmak istersek Encoding konusu karşımıza çıkmaktadır. Özellikle Türkçe karakterler içeren bir metni bir yazılım dili ile okumak istediğimizde encoding kesinlikle yapılması gereken bir işlemdir. Aksi takdirde karakterler tanınmayacağı için Türkçe karakterler okunan metin içerisinde tanımlanamayan karakterler olarak görünecektir.
Bu Türkçe karakter sorununu aşabilmek için mutlaka encoding işlemin düzgün yapılması gerekiyor. İşte bu yazımda neden doğru encoding yapılması gerektiğini, bu Türkçe karakterlerin neden okunamadığının arkasındaki temel soruna bakacağız. Kısacası ASCII tablosundan öncesine gidip, ASCII tablosunun ortaya çıkışını ve gelişmesine göz atacağız.
Encoding işlemini güzel bir şekilde anlayabilmek için bilgisayar sistemlerinin temeli olan 0 ve +5 volt elektrik sinyallerinden başlayacağız.
Karakter Kodlaması (character encoding)
Bir çoğumuzun bildiği gibi bilgisayar, bilgisayarı oluşturan parçalardaki devreler üzerinden geçen elektrik sinyallerini bizlerin görebildiği hale getirmektedir. Açtığınız internet browser, dinamiknetwork sitesi ve bu okuduğunuz yazı bile sadece elektrik sinyallerinin yorumlanması sayesinde görünür hale geliyor.
Bir devrede elektrik yok ise o devrenin değeri 0 volt, elektrik var ise o devrenin değeri +5 volt gibi bir değerdedir. (+5 volt yaklaşık bir değerdir.). Bu durumu incelediğimizde bir devrede elektrik var ise +5 yok ise 0 ‘dır. Binary yani ikili sistemlere baktığımızda da sadece 0 ve 1’i görürüz. Bu iki kavram bir araya getirildiğinde bir devrede elektrik var ise +5 volt yani 1, devrede elektrik yok ise 0 volt yani 0 anlamına gelir.
Devrede elektrik olması durumu +5 volt, 1 Doğru (Var) (True), olmaması durumu 0 volt, 0 Yanlış (Yok) (False) olarak yorumlanır. Bilgisayar açısından bilinen tek şey devrede elektrik olup olmadığıdır. Devrede elektrik olup olmamasını biz az önce bahsettiğimiz gibi 0 ve 1 ile yorumlarız. Burada, devredeki elektrik durumunu ikili (Binary) sistem olan 0 ve 1 ile kodlamış oluyoruz.
Bu elektrik sinyalleri ile bir işlem yapılamaz. Yani 0 volt ile +5 volt olan elektrik sinyallerini toplayamaz ya da çıkaramayız. Bizim, aritmetik işlemlerimizi yapacak değerlere ihtiyacımız var ki bu değerleri de az önce bahsettiğimiz ikili sistem sağlıyor. Devre üzerinden elektrik sinyallerini 0 ve 1 ile yorumladıktan sonra istediğimiz her türlü aritmetik işlemi yapabiliriz.
Üretilen ilk bilgisayarlar da işte tam olarak bunu yapıyordu. Kodlanmış olan elektrik sinyallerini hesaplamalar yapabilmek için kullanıyorlardı. Ancak hepsi buydu. İşin içinde harfler ve diğer karakterlerin yeri inanılmaz kısıtlıydı. Bir yazı metni oluşturmak o zamanlarda daktilo ve benzeri araçların görevi idi.
Zamanla bir fikir ortaya çıktı. Elektrik sinyalleri, aritmetik işlemlerde kullanılmak üzere sayılar olarak kodlanabiliyorsa, sayılar da metinlerde kullanmak üzere harfler ve karakterler olarak kodlanabilirdi.
Bilgisayarlar sadece elektrik sinyallerini görür ancak bilgisayarlardaki bu elektrik sinyallerinin hangi sayıları, hangi sayıların da hangi karakterlere karşılık geleceğini belirleyebiliriz. Bilgisayarlar elektrik sinyalleri ile çalışıyor olsa da bu elektrik sinyallerini nasıl yorumlaması gerektiğini belirleyebiliriz. Elbette bu durum tersi yönde de çalıştırılabilir. Dışarıdan gönderilen bir karakter önce sayılara sonra da elektrik sinyallerine dönüştürülebilir.
Bu iki yönlü dönüşüm işlemine de character encoding deniyor.
Karakter Kodlaması (character encoding) Nasıl Yapılacak?
Buradan yola çıkarak, sinyalleri sayılara, sayıları da karakterlere dönüştüreceğiz. Peki hangi sayılar hangi karakterleri temsil edecek? 1 sayısı hangi karakteri temsil edecek? ya da 10 sayısı hangi karakteri temsil edecek?
Bu soruların tek bir cevabı var. Bir kodlama tablosunun hazırlanması gerekiyor. Bir kodlama tablosu hazırlandığında, hangi sayıların hangi karakterleri temsil ettiği rahatlıkla belirlenebilir.
1960’lı yıllarda her bilgisayar üreticisinin kendine özel kodlama tabloları vardı. Yani her bilgisayar üreticisi bu kodlamaları farklı yapıyordu. Bir üretici için 10 sayısı A karakterini temsil ederken başka bir üretici de 10 sayısı C karakterini temsil edebiliyordu. Bu durumun en doğal sonucu ise bilgisayarlar arasındaki haberleşmenin inanılmaz zor hale gelmesi idi. Bilgisayarların sahip olduğu farklı kodlamalar yüzünden bir bilgisayardan diğerine gönderilen veri farklı kodlama tabloları yüzünden tamamen anlamsız hale geliyordu.
Tabi bu durum güvenli bir haberleşmeyi de zorlaştırıyordu.
Bu sorunun çözümü ise, nasıl elektrik sinyallerinin varlığı 1 yokluğu 0 olarak standart hale geldiyse bu kodlama tablosunun da bir standart haline gelmesi ve her üreticinin belirlenen bu standart kodlama tablosunu kullanması idi.
Standartlaşmanın Önemi
Standartlaşma, insanlığın gelişmesindeki en önemli yapı taşıdır. Eğer standartlaşma olmasaydı büyüme ve ilerleme imkansız olurdu. Eğer standartlaşma olmasaydı şu anda A1, A2, A3, A4 gibi kağıt formları olmazdı. Her kağıt üreticisi seçtiği bir yazıcı türüne göre kağıt üretirdi. Bu durumda her biri farklı boyutlardaki kağıtlar ile çalışan yazılarımız için uygun kağıt bulmak çok zor hale gelirdi. Ya da evlerimizdeki avizelere taktığımız ampüllerin girişleri için bir standart olmasaydı, ampüller patladığında avizemizin ampül girişine uygun bir ampül bulmak çok zor olurdu.
Bu duruma binlerce örnek verilebilir. Musluklarda kullanılan contalar, kullandığımız piller vs. Her biri belirlenen standartlara uygun üretildiği için yenisi almak istediğimizde herhangi bir yerden uyacak mı düşünmeden alabiliyoruz.
Bu durum bilgisayarlar içinde geçerlidir. Eğer bu kodlama tablosu standart hale getirilmemiş olsaydı, kendi bilgisayarınızda hazırladığınız bir metni başka bir bilgisayarda göremezdiniz. Hazırladığınız metni doğru bir şekilde görebilmek için görüntülemek istediğiniz diğer bilgisayarda, sizin bilgisayarınızın üreticisi tarafından üretilmiş olmalıydı.
Eğer kodlama tablosu standart hale getirilmemiş olsaydı ve ben bu metni A firmasının ürettiği bilgisayarda yazıyor olsaydım, bu yazıyı sadece A firması tarafından üretilen bilgisayara sahip olan kişiler okuyabilirdi.
1960’lı yıllarda da kodlama tablosu üzerine bir standartlaşma olmadığı için aynı şirkette çalışan kişiler bile birbirlerine dosya gönderdiğinde sorunlar yaşayabiliyorlardı. 1960’lı yılların başında Bob Bemer adlı bir bilim adamı ve IBM çalışanı, içinde oldukları bu büyük kargaşanın sona ermesi gerektiğine inanıyordu. Bu kargaşanın sona ermesi için, tüm üreticiler tarafından benimsenebilecek bir kodlama sistemi üzerinde çalışmalara başladı. ASCII tablosu da bu fikir sayesinde hayatımıza girmiş oldu.
NOT: ASCII, aski diye okunur. 🙂
ASCII Tablosu
Her karakterin, elektrik sinyallerinin kodlanması sayesinde oluştuğunu artık biliyoruz. Elektrik sinyalleri 0 ve 1 sayıları ile eşleştiriliyor, 0 ve 1 ile sayılar üretiliyor. Üretilen sayılar ise harfler ile eşleştiriliyor.
Yukarıda standartlaşmanın öneminden bahsetmiştik. Elektrik sinyallerinin 0 ve 1 olarak yorumlanabilmesi içinde bir uzlaşmaya varılması gerektiği aşikar. Yani devrede elektrik olmaması durumuna pekala 1 denebilirdi. Eğer bu noktada bile bir uzlaşma olmasaydı, ilk olarak hangi sayıların hangi sinyallere denk geldiği hakkında bir karar verilmesi gerekirdi.
Devrede elektriğin olmaması 1 olması 0 olarak yorumlanması pek akla yatkın bir kodlama olmadığı için bu konuda uzlaşmaya varmak zor değildi. Ancak iş karakterlere geldiğinde durum bu kadar basit değil. Dünya üzerinden bir çok dil var ve bu bir çok dilin kullandığı çok farklı karakterler var. En basitinden Türkçe karakterler buna örnektir. Latin alfabesi nispeten rahat. Peki ya Rusça? Arapça, Çince, Japonca? Bu diller tamamen farklı alfabeler kullanıyor. Her farklı alfabe demek onlarca farklı karakter demektir.
Bu kargaşayı ortadan kaldırmak amacı ile Bob Bemer ve ekibi, hangi sayıların hangi karakterleri temsil edeceği konusunda standart olacak bir tablo oluşturdular. Oluşturulan bu standarda “American Standard Code for Information Interchange” yani “Bilgi Alışverişi için Standart Amerikan Kodu” adını verdiler. ASCII adı da bu ismin kısaltmasıdır.
ASCII adı verilen sistem bazı sayıların bazı karakterler ile eşleştirildi basit bir tablodur. Elbette ilk zamanlar bilgisayarlar sadece Amerika içerisindeki pazarlarda yer aldığından diğer dillerdeki karakterler hesaba katılmadı ve ASCII tablosu sadece İngizlice harflerini içeriyordu.
7 Bitlik ASCII Sistemi
7 bitlik ASCII sisteminde en fazla 127 karaktere yer verilebilmektedir. Bu yüzden ASCII tablosu 7 bitlik bir sistemdir. 127 karakter sınırının sebebi ise 2^7=128 (2 üzeri 7) olmasıdır. Yani 128 adet sayı 7 bite karşılık gelmektedir. Bu durumda 0 sayısı da dahil olmak üzere 7 bitlik sistemde gösterilebilecek maksimum sayı 127 olmaktadır.
Aşağıdaki tabloda görebildiğiniz gibi ilk 32 karakter göremediğimiz yani basılamayan karakterlerdir. Bunlar bilgisayar sistemlerinde kendilerine özel işlevleri vardır. Tablonun tam halini buradan görebilirsiniz.

Örneğin 0. karakter boşluğu temsil eder. Burada dikkat etmeniz gereken şey space tuşunun bıraktığı boşluğun bilgisayar sistemlerinde 32. karakteri temsil ediyor olmasıdır. Yani bilgisayar sistemleri için gerçek boşluk space tuşu değil 0. karakter olan NULL’dur . 0. karakteri hiç bir elektrik sinyalinin olmadığı şeklinde yorumlayabiliriz.
Kaçış Dizileri – Basılamayan Karakterler
Bu ilk 32 karaktere Kaçış Dizileri denmektedir. Yukarıdaki ASCII tablosundaki ilk 32 karakterin detaylandırılmış hali aşağıdaki tablodaki gibidir. Ancak bir ASCII tablosunu incelediğinizde aşağıdaki gibi bir tanımlama göremezsiniz. Yukarıdaki tabloda [] ‘ler arasında yazılan ifadelerin bilgisayar sistemlerindeki tam karşılığı aşağıdaki tablodaki gibidir. Yazılımcı arkadaşların bir çoğunun aşağıdaki \t, \r ve \n ifadelerinin yabancı olmadığını düşünüyorum.
Şahsen bir çok yerde string ifade içerisinde alt satıra inmek için “\r\n” kullandığımı hatırlıyorum.

İlk 32 karaktere biraz bakacak olursak bir çoğu anlamadığımız şeylerdir ancak bazıları var ki biz yazılımcılar tarafından tanınmaktadır.;
- 9. sırada yer alan [HORIZONTAL TAB] ( \t ), sekme oluşturan kaçış dizisidir. (Kısaca TAB tuşu)
- 10. sırada yer alan [LINE FEED] ( \n ), satır başına geçiren kaçış dizisidir. (Kısaca HOME tuşu)
- 13. sırada yer alan [CARRIAGE RETURN] (\r), satırı başa alan kaçış dizisidir. (Kısaca ENTER tuşu)
Yukarıdaki ASCII tablosunda İngilizce olarak verilen kaçış dizilerinin hepsinin açıklamasını aşağıdaki tabloda görebilirsiniz.
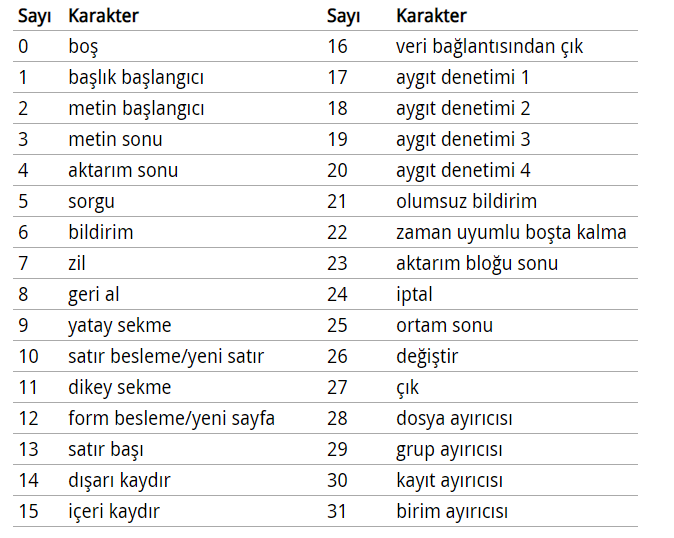
Buradaki tüm ifadeleri net olarak bende bilmiyorum. Bu yüzden hepsini açıklayamayacağım. Bunun için internette araştırma yapabilirsiniz.
Bu karakterlere aynı zamanda Kontrol Karakterleri ‘de denmektedir çünkü bu karakterler metin akışını kontrol etmek için kullanılır. Bu karakterler bir metin içerisinde oldukları gibi görünmezler. Bir metin parçasının nerede başlayıp nerede biteceğini, girintileri ve çıkıntıları yani bir metin parçasının sayfanın neresinde görüneceğini belirlerler.
Bunların haricinde kalan 32 ve 127 sayıları arasında kalan karakterler ekranlarda görünen yani metinleri oluşturan karakterlerdir. Bu karakterler sayesinde metin görüntüleme ihtiyacımızın büyük bir bölümünü karşılayabiliyoruz.
1960’lı yılara gelindiğinde bilgisayarlar çoktan 8 bir uzunluğundaki verileri işleyebilecek kapasitedeydi. ASCII sisteminin hayata geçirildiği bilgisayarlar 8 bitlik kapasiteye sahiplerdi ve bu 8 bitlik kapasitenin 7 bitlik kısmı karakterler için ayrılmıştı. Belirlenen bütün karakter 7 bitlik alana sığdırılmıştı. Boşta kalan 8. bit ise veri aktarımının düzgün bir şekilde yapılıp yapılmadığını denetlemek amacı ile doğruluk kontrolü için kullanılıyordu. Bu kontrole teknik olarak parity check yani eşik denetimi deniyordu. Bu denetimi yapmak için kullanılan bit alanına da parity bit yani eşlik biti deniyor.
ASCII adında geçtiği gibi bir Amerika standardıdır. Bu yüzden içerisinde Türkçe karakterleri barındırmamaktadır. ASCII Tablosu ‘nun her ne kadar bu gibi eksiklikleri olsa da son derece yaygın bir kullanım alanı vardır. Bazı sitelere üye olurken Türkçe karakter kullanamamamızın sebebi de ASCII Tablosu temel alınması sebebiyledir.
Genişletilmiş ASCII Tablosu
ASCII 7 bitlik bir kodlama tablosudur. Ancak zamanla 8. bitin kontrol amacı ile kullanılmasından vazgeçildi. Bu sebeple 8. bit boşa düşmüş oldu. 8. bitin boşa düşmesiyle de ASCII Tablosuna 128 karakter daha eklenebilir hale geldi. 7 bitlik sistemde karakter sınırı 2^7 = 128 ise 8 bitlik sistemde karakter sayısı 2^8 = 256 karakter olacaktır.
Bu 8. bit ile ortaya çıkan 128 karakterlik alanda farklı kişi ve kurumlar tarafından İngilizce’de bulunmayan karakterleri temsil etmek için kullanıldı. Elbette 8. bit alanı ile açılan 128 karaktere tüm karakterlerin sığdırılması mümkün değil. Bu sebeple kod tablolarının farklılaşması kaçınılmaz hale geldi. Bu farklılaşmış kod tablolarına kod sayfaları adı verildi.
Örnek vermek gerekirse Microsoft Şirketinin Türkiye’ye gönderdiği sistemlerde yer alan “cp857” kodlu kod tablosunda Türkçe karakterlere de yer verilmiştir. Microsoft’un Arapça konuşulan ülkelere gönderdiği ASCII tablosu da bu bağlantıda görebileceğiniz gibi 708 numaralı kod sayfasıdır.
Code Page 857 = CP857
Bu kod sayfalarının çokluğu sebebiyle yazılım dillerine Encode() metotları eklenmek zorunda kalınmıştır. Bu metot sayesinde yazılmış olan metinleri başka bir kod sayfasına göre yorumlanmasını isteyebiliriz.
Türkçe bir metni okuyup programımıza göstermek istediğimizde Encode() metodu ile Türkçe karakterleri içeren bir kod sayfası üzerinden yorumlanmasını isteyebiliriz. C# programlama dilinden örnek vermem gerekir ise, StreamReader sınıfı ile bir dosya okumak istediğimizde encoding tanımlanmaz ise Türkçe karakterler soru işareti olarak görünecektir. Ancak günümüzde çok fazla sayıda kod tablosu üretildiği için Türkçe karakterleri okumanında bir çok yolu var.
string yardim = "";
StreamReader sr = new StreamReader("C:\\metin.txt", Encoding.GetEncoding("iso-8859-9"), false);
yardim = sr.ReadToEnd();
sr.Close(); Yukarıdaki kod bloğunda, metin.txt dosyasının Türkçe karakterler içerdiğini ve ona göre okunmasını istedik. Ancak buradaki “iso-8859-9” yerine “windows-1245” yazarak da Türkçe karakterlerin doğru okunmasını sağlayabiliriz.
Bu kullanımdaki fark, oluşturulan metin belgesinin hangi kod tablosuna göre kodlandığı ile ilgilidir. Yani “iso-8859-9” ile kodlanmış Türkçe karakterleri “windows-1245” ile de okuyamayız. Hangi kodlama tablosuna göre kodlandıysa o kodlama tablosu üzerinden okuma yapmalıyız. Buradaki okumadan kasıt encode() işlemidir.
Eğer encoding kullanmadan okuma yapmaya çalışırsak, Türkçe karakterler içeren bir metni, Arapça konuşulan bir ülkeye gönderdiğimizde “cp857” tablosunda kodlanan Türkçe karakterlerin yerine “cp708” tablosunda kodlanan Arapça karakterler görünecektir. Çünkü yapılan eşleştirmeler aynı sayıyı adreslemektedir. Yani “cp857” tablosundaki 128. karakter ile “cp708” tablosundaki 128. karakter aynı değiller. Bu sebeple farklılıklar olacaktır.
ASCII ve Genişletilmiş ASCII Arasındaki Farklar
ASCII tablosu ile Genişletilmiş ASCII tablosu kesinlikle aynı şeyler olarak görülmemelidir. ASCII tablosu denildiğinde akla gelen tek şey 7 bitlik ASCII tablosudur. Genişletilmiş ASCII, ASCII tablosunu kapsayan bir tablodur. ASCII tablosu hiç bir zaman 128 karakter dışında bir karakteri temsil etmemektedir.
Genişletilmiş ASCII, çeşitli kurum ve kuruluşlar tarafından ASCII tablosu ile temsil edilemeyen *diğer karakterleri temsil edebilmesi için birbirlerinden farklı biçimlerde ***genişletilmesi ile ortaya çıkmış bir kavramdır. Yani ASCII tüm dünyada tek ve sabittir ama Genişletilmiş ASCII çok çeşitlidir ve ASCII’nin kendisi kadar standartlaşmamış bir sistemler bütünüdür.
Genişletilmiş ASCII tek başına bir karakter tablosunu (veri kümesini) temsil etmemektedir. Genişletilmiş ASCII’den bahsederken hangi karakter kümesi ile genişletildiği bilgisi de belirtilmelidir.
Bu standart her ne kadar yıllarca güvenli veri aktarımı için kullanılmış olsa doğası gereği dünyadaki diğer dillerde yer alan tüm karakterleri içeremez. Bu nokta, bu standardın zayıf kaldığı noktadır. ASCII standardı bir karakterin 1 bayt ile temsil edilebileceği düşüncesi ile kurulmuştur. 1 bayt’ın 8 bit’e denk geldiğini biliyoruz ama bunun nedeni nedir? Aslında insanları tatmin edecek net bir cevabı yok. İnsanlar öyle istemişler ve öyle yapmışlar. Nasıl bir destenin 12 parçadan oluştuğuna karar verilmiş ise bu da onun gibi. Net bir sebebi yok.
ASCII tablosu 7 bitlik bir sistemdir. 128 karakter alabilir ve bu standart için en büyük sayı olan 127, 7 bit ile gösterilebilir.
Genişletilmiş ASCII, 8 bitlik bir sistemdir. 256 karakter alabilir ve bu standart için en büyük sayıl olan 255, 8 bit ile gösterilebilir.
Eğer 256 karakterden daha fazla karakteri temsil etmek istersek, bunun için bir karakteri temsil etmek için en az 2 baytlık alana ihtiyacımız olur.
Genişletilmiş ASCII tabloları arasında yaklaşık olarak aynı olan tablolar vardır. Mesela Microsft şirketinin kendine özgü bir çok dil için tablosu var. Ancak ISO kurumununda kendine özgü tabloları vardır. Microsoft’un Türkçe karakter desteği verdiği tablonun adı “cp857”dir ISO’nun Türkçe karakter desteği verdiği tablosunun adı da “iso-8859-9” dir. Benzer tablolar, farklı kurumlar ve farklı amaçlar için üretilmektedir.
ASCII Nedir? Tüm Detaylarıyla ASCII yazımda bu kadardı arkadaşlar. Diğer yazılarda görüşmek üzere…
Diğer yazılarıma gitmek isterseniz buraya tıklayabilirsiniz.
Sağlıcakla, güvende ve takipte kalın.
Bana destek olmak isterseniz bir kahve ısmarlayabilirsiniz veya diğer hesaplarımdan takip edebilirsiniz.







Teşekkür ederim.
Çok güzel bir bilgilendirme olmuş. Çok istifade ettim. İşi en basit şeklinden alıp anlayabileceğimiz hale getirmişsiniz.
Rica ederiz. Faydalı olmasına sevindik.